1 赛题描述
1.1 赛题背景
机器虽然被大量用到农业生产中,但人还是不可或缺的因素。通过农民身份识别,可以真实客观地记录农民的状态,为农场管理和农产品追溯提供真实的客观数据;较之直接存储视频,可以有效地降低存储空间;自动识别也比人工监管,大幅度提高效率,减少人工成本。
1.2 赛事任务
农民身份识别需要对农民进行分类,本次大赛提供了中国农业大学实验室视频制成的图像序列。提供了25名农民身份,每个身份包含10段视频制成的图像序列,选手需要对图像序列进行预处理,打标签,并对农民进行身份识别。参赛选手先对图像进行预处理,并制作样本,对图像中的农民进行识别。选手需要自行训练模型,并上传自己训练好的模型和权重。
这里实际上就是图像分类的问题,因为虽然是人物身份识别,但是所有的身份已经确定,仅包含在这25个人之中,因此实际上是图像分类的问题。
1.3 评价指标
本模型依据提交的结果文件,采用Macro-F1进行评价,其中Macro-F1的一种定义如下:
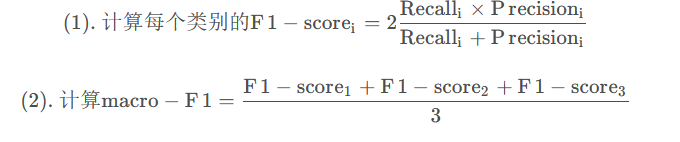

在“Training algorithms for linear text classifiers( Lewis, David D., et al. “Training algorithms for linear text classifiers.” SIGIR. Vol. 96. 1996.)”中,作者指出,第一种方式对错误的分布不太敏感。,Macro-F1应当是所有类中F1-score的平均值,即第二种方式才是Macro-F1的计算方式,因此我们使用第二种计算方式。
2 任务分析

可以观察到,这里的图像都是上下顶格的,考虑到边缘在CNN卷积的过程中会存在padding的情况,我们可以考试适当放缩图片,为边缘补充zero padding,保证图像效果。
测试集的评测标准是 macro-F1,但是似乎在两次实验中都没有发现使用F1有显著好于使用acc的情况,似乎说明了macro-F1在验证集的评价能力并没有显著高于测试集?
3 代码
1. 数据读取
# 数据读取
# 训练集
train_loader = paddle.io.DataLoader(
XunFeiDataset(train_path[:-1000], train_label[:-1000],
A.Compose([
A.RandomRotate90(),
A.Resize(256, 256),
A.RandomCrop(224, 224),
A.HorizontalFlip(p=0.5),
A.RandomContrast(p=0.5),
A.RandomBrightnessContrast(p=0.5),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
), batch_size=30, shuffle=True, num_workers=0
)
# 验证集
val_loader = paddle.io.DataLoader(
XunFeiDataset(train_path[-1000:], train_label[-1000:],
A.Compose([
A.Resize(256, 256),
A.RandomCrop(224, 224),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
), batch_size=30, shuffle=False, num_workers=0
)
# 测试集
test_loader = paddle.io.DataLoader(
XunFeiDataset(test_path, [0] * len(test_path),
A.Compose([
A.Resize(256, 256),
A.RandomCrop(224, 224),
A.HorizontalFlip(p=0.5),
A.RandomContrast(p=0.5),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
), batch_size=2, shuffle=False, num_workers=0
)
观察到这里是固定采用最后一千张作为验证集,因此可能会存在问题,这里我们在数据集开始划分的时候进行随机shuffle,保证数据集的划分更加具有随机性,并且是独立同分布的。
要注意,shuffle的话需要保证标签一起shuffle,之前改代码的时候遇到了这个问题,改了好久都没反应过来。(
2. 模型建立
- 保存最优模型,防止产生过拟合现象。
# 模型训练
def train(train_loader, model, criterion, optimizer):
model.train()
train_loss = 0.0
for i, data in enumerate(train_loader()):
input, target = data
input = paddle.to_tensor(input)
target = paddle.to_tensor(target)
output = model(input)
loss = criterion(output, target)
loss.backward()
optimizer.step()
optimizer.clear_grad()
if i % 100 == 0:
print('Train loss', float(loss))
train_loss += float(loss)
return train_loss/len(train_loader)
# 模型验证
def validate(val_loader, model, criterion):
model.eval()
val_acc = 0.0
for i, data in enumerate(val_loader()):
input, target = data
input = paddle.to_tensor(input)
target = paddle.to_tensor(target)
output = model(input)
loss = criterion(output, target)
# 这里是因为使用了cutmix,所以target的label也是软标签形式
# 其实我有点不确定这里是不是该用acc
val_acc += float((output.argmax(1) == target.argmax(1)).sum())
return val_acc / len(val_loader.dataset)
# 模型预测
def predict(test_loader, model, criterion):
model.eval()
val_acc = 0.0
test_pred = []
for i, data in enumerate(test_loader()):
input, target = data
input = paddle.to_tensor(input)
target = paddle.to_tensor(target)
output = model(input)
test_pred.append(output.data.cpu().numpy())
return np.vstack(test_pred)
for _ in range(100):
train_loss = train(train_loader, model, criterion, optimizer)
val_acc = validate(val_loader, model, criterion)
train_acc = validate(train_loader, model, criterion)
print(train_loss, train_acc, val_acc)
if val_acc > best_acc:
best_acc = val_acc
best_dict = model.state_dict()
print(' EPOCH {} Best accuracy is {:0.6f}'.format(_, best_acc))
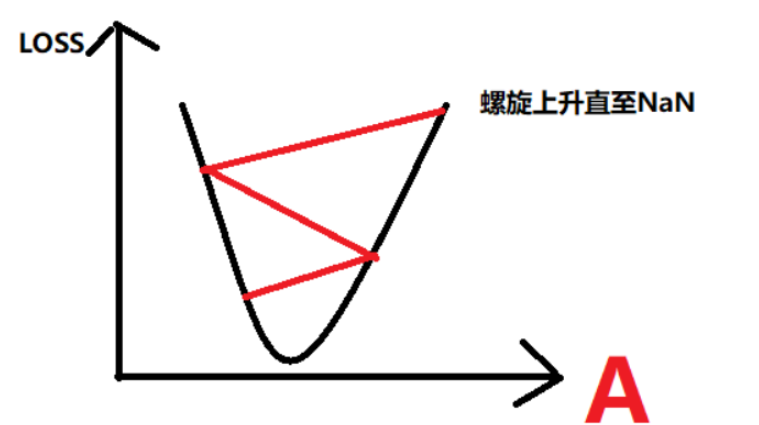
采用学习率的梯度下降,在最小值点提供更小的学习率,防止不收敛。之前同学们提到的0.2-0.5突然震荡回0.8就可能是这种情况。这里我的损失收敛到了0.05-0.12左右。使用了paddle的stepdecay策略,梯度下降学习率。
model = XunFeiNet() model = model criterion = nn.CrossEntropyLoss(soft_label=True) scheduler = paddle.optimizer.lr.StepDecay(learning_rate=1e-3, step_size=3, gamma=0.9, verbose=False) optimizer = paddle.optimizer.AdamW(parameters=model.parameters(), learning_rate=0.001)使用cutmix增强,防止类别不均衡的问题。
def rand_bbox(size, lam): if len(size) == 4: W = size[2] H = size[3] elif len(size) == 3: W = size[0] H = size[1] else: raise Exception cut_rat = np.sqrt(1. - lam) cut_w = int(W * cut_rat) cut_h = int(H * cut_rat) # uniform cx = np.random.randint(W) cy = np.random.randint(H) bbx1 = np.clip(cx - cut_w // 2, 0, W) bby1 = np.clip(cy - cut_h // 2, 0, H) bbx2 = np.clip(cx + cut_w // 2, 0, W) bby2 = np.clip(cy + cut_h // 2, 0, H) return bbx1, bby1, bbx2, bby2 # 自定义数据集 # 带有图片缓存的逻辑 DATA_CACHE = {} class XunFeiDataset(Dataset): def __init__(self, img_path, img_label, transform=None): self.img_path = img_path self.img_label = img_label if transform is not None: self.transform = transform else: self.transform = None def __getitem__(self, index): if self.img_path[index] in DATA_CACHE: img = DATA_CACHE[self.img_path[index]] else: img = cv2.imread(self.img_path[index]) DATA_CACHE[self.img_path[index]] = img label = paddle.zeros([25]) label[self.img_label[index]] = 1 # ------------------------------ CutMix ------------------------------------------ prob = 20 if random.randint(0, 99) < prob: rand_index = random.randint(0, len(self.img_path) - 1) if self.img_path[rand_index] in DATA_CACHE: rand_image = DATA_CACHE[self.img_path[rand_index]] else: rand_image = cv2.imread(self.img_path[rand_index]) DATA_CACHE[self.img_path[index]] = rand_image lam = np.random.beta(1,1) bbx1, bby1, bbx2, bby2 = rand_bbox(img.shape, lam) img[bbx1:bbx2, bby1:bby2, :] = rand_image[bbx1:bbx2, bby1:bby2, :] # masks[bbx1:bbx2, bby1:bby2] = rand_masks[bbx1:bbx2, bby1:bby2] lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (img.shape[1] * img.shape[0])) rand_label = paddle.zeros([25]) rand_label[self.img_label[rand_index]] = 1 label = label * lam + rand_label * (1. - lam) # --------------------------------- CutMix --------------------------------------- # print(f"[INFO]: label is {label}") if self.transform is not None: img = self.transform(image = img)['image'] img = img.transpose([2,0,1]) return img, label def __len__(self): return len(self.img_path)采用预训练Resnet50_64x4d作为骨架,修改全连接层为最后为25类。同时可以使用VGG,densenet等分别得到预测结果,最后使用集成的方法。我这里使用了简单投票,其实可以考虑更有效的集成方法。
class XunFeiNet(paddle.nn.Layer): def __init__(self): super(XunFeiNet, self).__init__() model = models.resnet101(True) model.avgpool = paddle.nn.AdaptiveAvgPool2D(1) model.fc = nn.Linear(512, 25) self.resnet = model def forward(self, img): out = self.resnet(img) return out class XunFeiNet(paddle.nn.Layer): def __init__(self): super(XunFeiNet, self).__init__() self.net = paddle.hub.load('PaddlePaddle/PaddleClas:develop', 'resnext50_64x4d', source='gitee', force_reload=False, pretrained=True) self.linear = nn.Linear(1000, 25) def forward(self, x): x = self.net(x) x = self.linear(x) return x防止过拟合的几种方法
早停:即在验证集上的性能不再提升时,停止训练。这样可以防止模型在训练集上过度学习。
正则化:在损失函数中加入L1或者L2正则项,防止模型权重过大。
Dropout:随机丢弃一些节点的输出,可以增加模型的鲁棒性。
数据增强:通过对训练数据进行变换,从而创建新的训练样本,使模型更容易泛化到未见过的数据。
使用更小的网络结构:减少模型的复杂度,避免过拟合。TTA 集成学习的思路较为简单,若某一个预测器件的准确率大于50%,那么很多个这样的预测器对结果投票得出的结果准确率将会更高。类似于模型集成,增加了鲁棒性,在测试时通过各种数据增广,在得到结果后再综合得到输出。